

Що вміють і роблять прикладні лінгвісти
За результатами виробничої практики з фаху на кафедрі перекладу, прикладної та загальної лінгвістики пройшло обговорення результатів лінгвістичного блоку практичної підготовки здобувачів освітньої програми «Філологія (прикладна лінгвістика (англійська мова) і германські мови та літератури (переклад, англійська мова включно))».
Одним із наріжних каменів підготовки сучасного філолога і лінгвіста є вміння працювати з лінгвістичними корпусами мови — великими спеціалізованими базами даних (оцифрованих та метарозмічених текстів), що уможливлюють складні алгоритми пошуку та забезпечують статистично релевантні дані про вживаність і частотність тих чи інших мовних явищ, які об’єктивують наші уявлення про «природне» і «неприродне» в літературній і живій мові, про узвичаєний слововжиток (узус) та реальні контекстуальні еквіваленти в текстах перекладного походження.
Лінгвістичних корпусів української мови існує не так багато, як хотілось би. Із найбільшим із них — Генеральним регіонально анотованим корпусом (ГРАКом), що функціонує на рушії Sketch Engine і базується на серверах Єнського університету імені Фрідріха Шиллера (Німеччина) — наші здобувачі вже знайомі, оскільки ще позаминулого року мали академічну мобільність у цьому університеті та проходили сертифікований курс із цифрової української філології (90 год.)
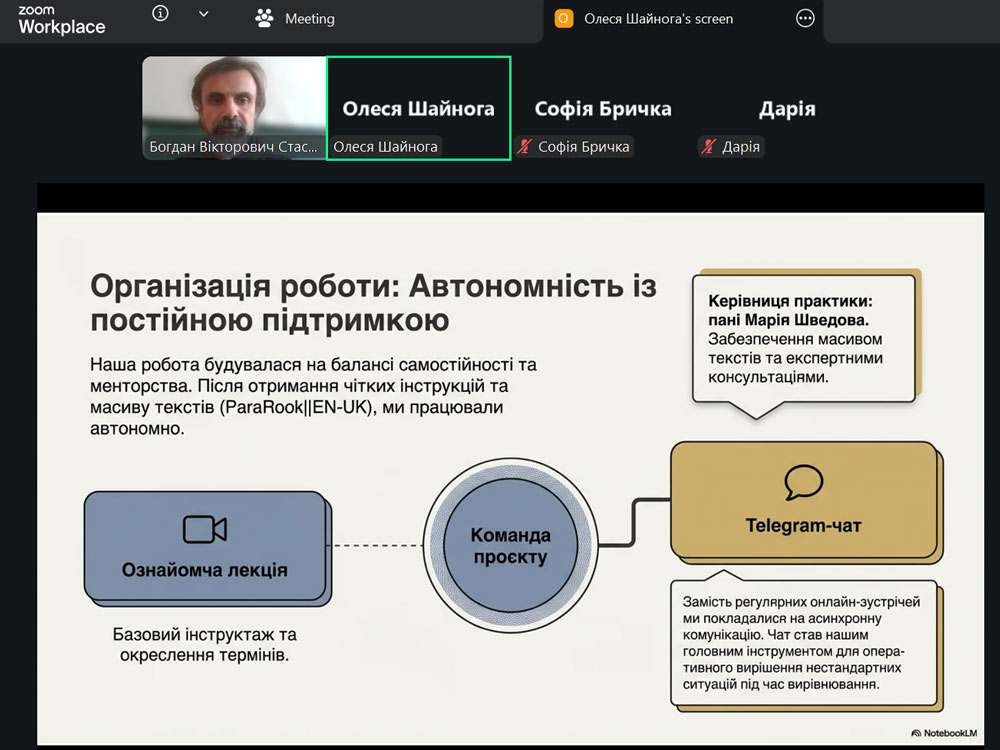
Цього ж року, в рамках виробничої практики та під керівництвом уже знайомої нашим здобувачам дослідниці, провідної корпусної лінгвістки доц. Марії Шведової (кафедра інтелектуальних комп’ютерних систем Національного технічного університету «Харківський політехнічний інститут»), студенти опановували значно молодший паралельний корпус англо-українських та німецько-українських перекладів ParaRook. У їхні задачі входило опрацювання й підготовка існуючих українських перекладів для додавання в цей корпус. Просте на перший погляд завдання, насправді, передбачало цілу низку нетривіальних етапів: розпізнавання та чистку англійських та українських текстів, їхнє актуальне членування, вирівнювання по сегментах (реченнях та абзацах) та виявлення невідповідностей між ними в спеціальному програмному середовищі InterText, коментування незбіжностей і — насамкінець — метарозмітку отриманих файлів у форматі tmx. Пильної уваги наших прикладистів удостоїлися новітні і класичні переклади Дена Брауна, Фрідріха Глаузера, Ґерхарда Гольц-Баумерта, Марґарет Етвуд, Джессі Келлермана, Стефані Маєр, Сомерсета Моема, Дафни дю Мор’є та Філіпа Пулмана.
Усі ці тексти тепер збагатять паралельний лінгвістичний корпус українських перекладів і дозволять у подальшому покращити двомовні словники, об’єктивізувати дескриптивні перекладацькі студії та поліпшать тренування національної великої мовної моделі (LLM), що не так давно отримала своє ім’я — «Сяйво». Приємно знати, що в її підготовці буде закарбована праця і наших майбутніх випускників.
А закріплять свій практичний досвід здобувачі на нормативному курсі корпусної лінгвістики, який стартує вже зараз.
P. S. Розкриємо маленьку таємницю. Не так давно наша кафедра уклала договір про співпрацю з розробником та адміністратором іще одного важливого лінгвістичного ресурсу, національного корпусу української мови — Мовно-інформаційним фондом Національної академії наук України (УМІФ НАНУ). Ми вже готуємо з ними спільні проєкти, і сподіваємося, що в новому навчальному році нинішні 3-курсники зможуть апробувати співпрацю з найповажнішим розробником лінгвістичних програмних ресурсів у нашій країні.

